导读 INTRODUCTION
本文作者:郭朝晖博士,优也首席科学家,前宝钢研究院首席研究员,中国工业智能领域权威专家。由「控制工程中文版」CEChina原创首发。
为什么工业大数据的数据建模如此重要?在建模过程中,企业首要考虑的因素有哪些?又该如何搭建一个符合自身实际需求的模型呢?
请看下文原宝钢首席研究员、工业大数据资深专家郭朝辉博士,在2022(第十一届)全球自动化和制造主题峰会上的演讲内容整理。
图片来源 :CEChina
郭朝晖演讲内容梗概

工业大数据建模:两个灵魂拷问
Q1
为什么有了理论模型,还要数据建模?
任何一个理论模型都需要参数,牛顿定律也不例外,更何况对于复杂的工业系统,若干个子系统都需要各自的参数。但这些参数往往是吃不准,或者有很大误差,或者没法测量,在这个情况下,机理模型不是没有,而是没有用的条件。

工业中有大量知识,这些知识的特点是都可以用物理学原理推导出来。即使算不出来也没关系,把它记录下来下次就会有标准和依据。它也不是理论推导不出来,而是不方便推导,在应用过程中,直接用实际的结果来算就完事了。
Q2
很多工业关键知识都实现了标准化,
为什么还要建模?
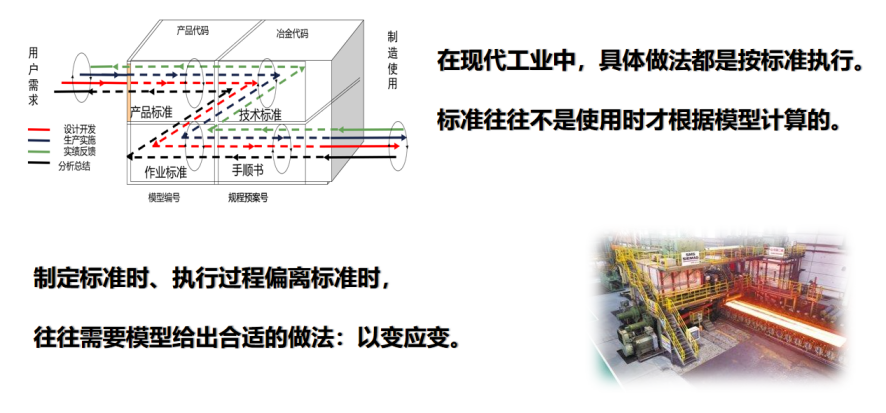
标准往往都是固定的,所以应对不稳定的生产过程,标准是需要修改的。静态的标准往往不成,我们需要用动态标准来以变应变,这就需要用模型来帮助我们制定标准,所以模型其实也是有用的。
解决完这两个问题,我们要知道标准从何而来。在工业大数据时代,有一种很好的办法——历史上这样发生过,下次再出现问题,就让计算机“跟着学”(NN、KNN、CBR)。我们不用把它想的太复杂,比如深度学习、神经元等,在多数情况下都没那么复杂。
然而,在数据不多的时候,能跟着谁去学呢?过去,对一台设备的故障进行诊断,数据记住后,故障如果十年发生一次,再过10年设备就报废了,有了数据也没机会学。而工业互联网,可以把成千上万台类似的设备放在一起,发生一次故障就可以作为一个知识记下来,这也是工业大数据真正的意义所在。

常见的模型:基准选择+矫正
至于如何提高模型精度,由于生产过程参数在不断变化,“一竿进洞”往往很难达到,这就需要我们分步走,即首先跟着成功案例,选择一个基准来学习,再根据差别进行补缺和调整,以获得更高的精度。当然,现实中调整是需要数据来提供支持的。
比如说X测不到,但你知道变量Z,就可以根据它的变动来做调整。在工业大数据的背景下,数据条件也会越来越好,跟X接近的变量会越来越多,模型也会越来越好。然而,这个过程中也会产生新的问题。过去是Y=f(X,C),用了Z后真正的数据模型就是Y=H(Z,C),选不同的Z,H就会不一样。所以工业过程由于缺少数据,由于变量不同,数据模型的结果可能也完全不一样。

现实数据模型和理论模型不一样
那么,工业建模在数据不完整的情况下,如何选择变量?我们需要明确一点,精度并不代表一切,应用价值好才是最终目的。这看似不能接受,但哪怕是微积分在内也是这样。数据建模和机理模型往往是不一样的,但是在一定的范围内有用就行了。

正确认识现实的模型:对错与实用是两码事
当然,在工业大数据的基础上,我们有机会在保障精度的同时追求真实性,这就是所谓的“第四范式”。但这个事情非常难,可能需要一二十年的功夫,因此多数企业在做选择时要慎重。精度、正确性和它的应用范围,有可能是存在矛盾的,要根据实际的需求来决定。
理解实用的模型:精度与可靠性
实用模型的关键有三点:精度、应用范围,以及二者是否是可知和稳定。众所周知,工业领域对于稳定性的要求非常高,模型正确的时候能带来好处,但错误的时候同样会带来坏处。人们常说的平均精度高,就是需要在过程稳定的时候高,而稳定可能占了99%的情况,但人们往往是在过程不稳定的时候需要模型。

传统模型往往只适合特殊情况,因此,如果精度不能持续,精度再高都没用。工业大数据之所以能适合于各种各样的场景,是因为它能拿到对象方方面面的属性,且提供了更多角度来识别场景,以便在具体场景下,也能做识别和精度调整。
此外,很多人对机器学习也有理解偏差。首先,机器学习并不意味着要做多么复杂的模型;另外,智能化时代的模型往往针对大系统,而大系统的参数本身是不断漂移的,如果没有跟着漂移的机制,模型用几天就慢慢不能用了,所以针对生产过程的模型,机器学习就是来应对模型参数漂移的。

此外,只要是基于数据的定量模型,几乎都会有误差,当然有的逻辑模型可能没有误差,或者有的能知道有多大误差等。因此,我们就要考虑误差和应用场景需求的匹配,这非常重要。
实用模型的背后:数据质量是关键
模型使用的根本是高质量的数据。当建立数学模型的时候,人们总希望它的稳定度高,而现实中不稳定是一种常态,对同一对象,这个月和下个月建出的模型,它的数据参数会相差很远。
有一个重要的原因是,我们建模总会在一个工作点,或者特定的场景附近,这样做测量的时候,它的波动相当大的一部分,不是对象参数的波动,而是由于测量过程的干扰。测量精度决定了控制精度,测量误差和实际波动,往往是处在一个数量级上的。
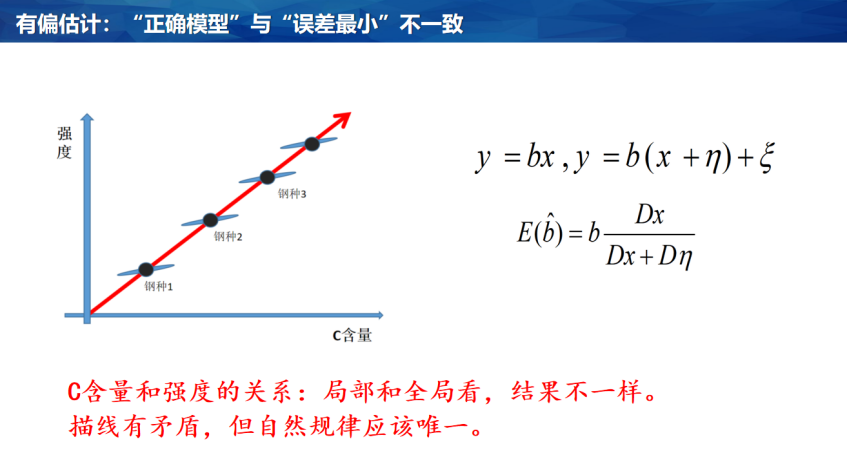
此外,在建模的时候,输入误差不可忽略,这就会导致“有偏估计”,即误差最小的模型往往是错的,因为输入是错的,误差小是“错错得对”引发的。任何一种方程或是建模方法,只要你追求的是误差最小,其实它都会偏离真实的问题。
因此,在模型精度不高时,首先应该关注的不是算法,而是数据质量。宝钢信息技术的奠基人何麟生先生曾提过“数据不落地”,即为了保证数据的真实性,数据的产生和存储过程不经过人。因为很多数据,不是为了建模而产生的,它的质量往往不能达到要求。这涉及到了数据采集过程的标准化,只有解决数据的质量问题,才能把数据建模做好。
工业大数据的意义在于促进智能化
除此之外,数据建模的基本条件,是要让数据的因果关系能对应得上。这听起来简单,但做起来难。数据质量不仅是数据精度的问题,更重要的是数据对应关系,这与采样频度等因素息息相关。我们要知道,工业大数据并不等同于互联网大数据。工业大数据数据“大”,并不能保证做的好,但是数据“大”能为提高数据质量创造条件,并为后期数据建模、根因分析铺平道路。
软件角度看模型:关键还是可靠
现代工业,尤其是自动化程度很高的行业,执行工艺都会让计算机执行,所以现代化工业知识和诀窍,也都写在计算机里面。因此如果不懂计算机软件,是把握不住工艺的细节的,学习知识就会面对“天花板”。

从工业软件的角度认识“模型”
早在20多年前,当时本人建议宝钢公司重视数学模型,领导也给予了充分重视。通过知识和数学模型计算的融合,宝钢经过10多年的努力,全部掌握了引进技术,彻底解决了这类问题,中国钢铁行业再也不会被卡脖子了。
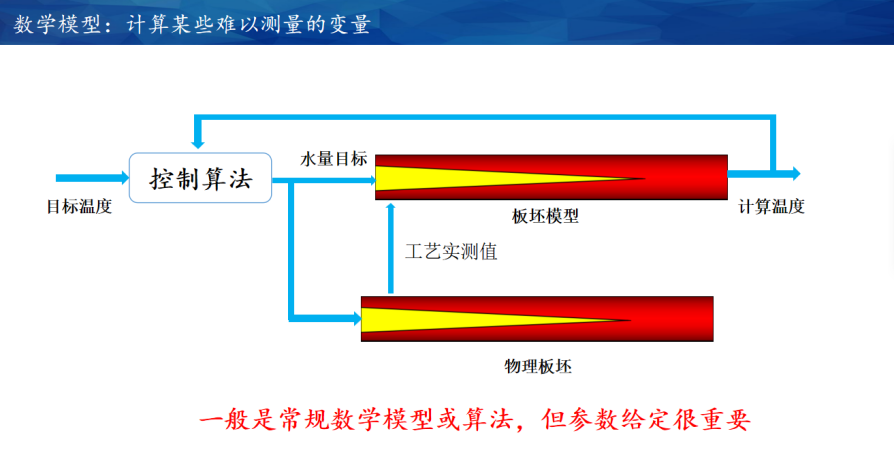
那么,工艺的数学模型是什么?举个例子,工业生产的过程中,在各种事件和场景变化下,我们想要控制某个参数,比如一个钢胚的表面温度,这和传统控制的固定工作点做自动控制是不一样的,需要计算和数学模型两者间进行融合。
有一种计算机概念叫“自动机”,而工业界所说的数学模型,其实就是一种工业APP。要在工业场景不断变化的过程中执行任务,完成控制靠自动化能力,而感知场景的不断变化,则需要通过信息系统,因此,信息系统和控制系统的集成至关重要。

现如今,模型开发80%的时间都会花在保障可靠性上,这也是难点所在。比如要考虑模型运行是否会出现意外、歧义和异常,处理异常的方法是否完备等,为了稳定可靠性,模型的编程方式也会不一样。

软件开发追求的重点不是效率、新颖,而是稳定
我个人认为,软件编程开发适合“有罪推定”原则,即如果你不能证明你的代码是正确的,你就要拿回去重写。因为现场无小事,无论是软件开发还是建模的过程,开发效率高、模型精度高都是次要的,安全稳定性才是最重要的,只有这个问题解决了,模型的实用性才能得到保障。